NPU Chip Design & Verification — CNN Accelerator (Tape-out)
Silicon-validated22 nm CNN inference NPU, pre-silicon verification ownership through tape-out and silicon validation.
- Role
- Team-developed; personal ownership: pre-silicon verification
- Dates
- Feb 2026 – present
- Verif
- AI
- RTL
- NPU
One-line hook: collaborative 22nm CNN inference NPU; took a LeNet-style network through RTL → tape-out → silicon validation; personal ownership on pre-silicon verification (UVM env, scoreboard, coverage closure, CDC sign-off).
Role
- Project type: collaborative chip development with industry mentors
- Network: CNN inference (LeNet-style, MNIST / CIFAR-10 class)
- Personal ownership: pre-silicon verification — UVM environment, scoreboard with bit-accurate reference models, coverage closure, CDC sign-off across 4 async clocks
- Design contributions: reviewed and co-developed selected modules (FP16 MAC datapath, AXI/APB/SPI bus integration, clock-mux / reset-sync paths)
Tech Stack
SystemVerilog · UVM · Synopsys VCS / Verdi · AXI VIP · SPI agent · RAL (SPI→APB adapter) · CDC sign-off · coverage-driven verification · Python regression harness
Architecture
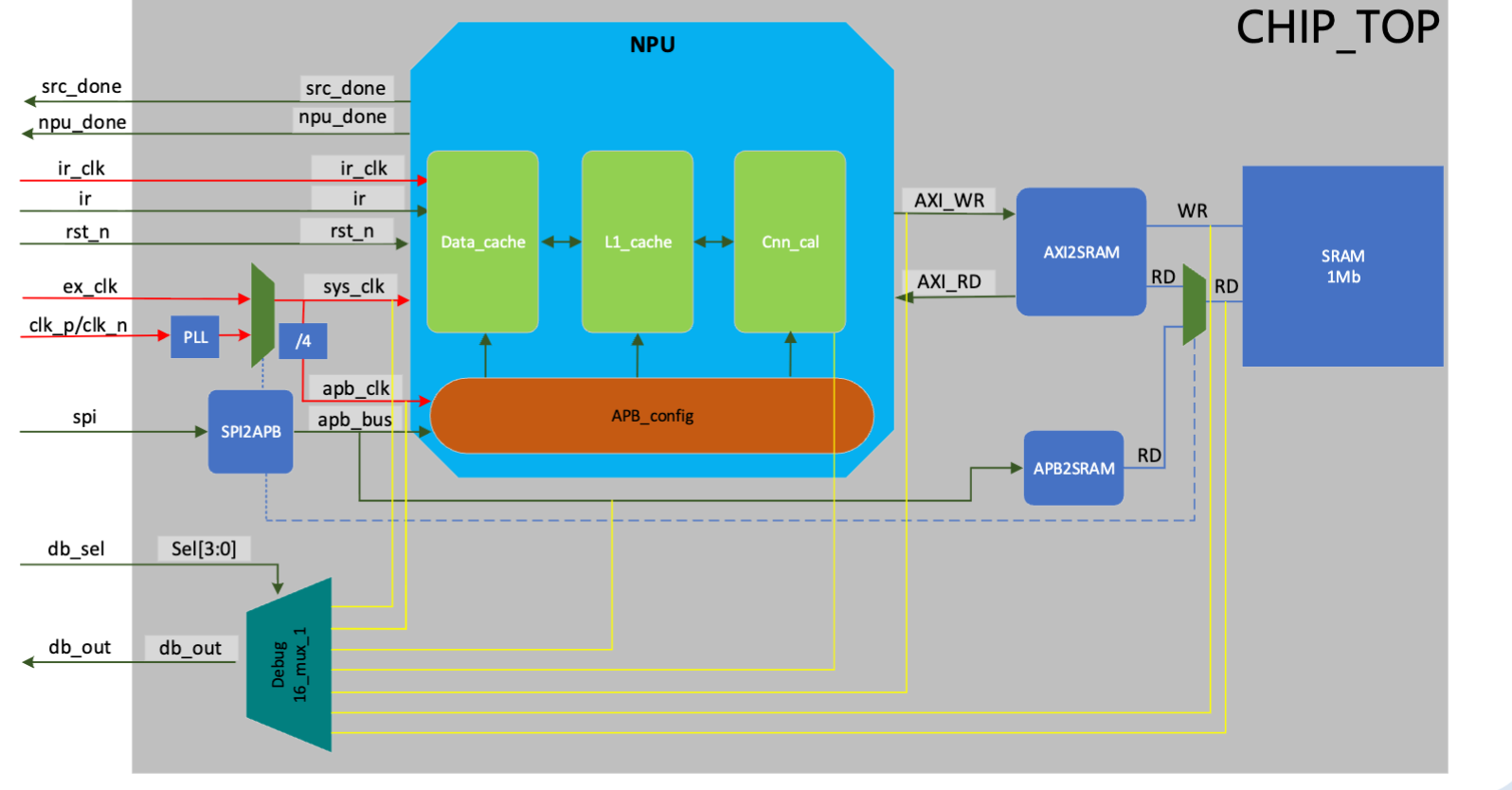
Chip-top integration: NPU compute core (Data_cache + L1_cache + Cnn_cal + APB_config) sits between an AXI-based data path (host SRAM ↔ chip via AXI2SRAM) and an APB control path (host registers ↔ chip via SPI2APB → APB2SRAM). A debug mux (Debug_16_mux_1) brings selected internal signals out to a top-level pin for board bring-up. Four async clock domains — ir_clk, sys_clk, apb_clk, plus the SPI clock — are crossed with sync-bit and async-FIFO primitives.
CNN inference datapath:
Image (INT8) → AXI ingest → Cache
→ INT8 → FP16 dequant
→ Conv (multi-channel MAC + add-tree)
→ ReLU
→ MaxPool 2×2
→ Conv → ReLU → MaxPool
→ FC → ReLU → FC → MaxResult (classification)
→ AXI write-outVerification Highlights
- Built full-chip UVM environment on Synopsys AXI/SPI VIP with a custom image UVC (RGB raster stimulus) and RAL via SPI→APB register adapter.
- Authored vplan + UVM sequences for register read/write, MNIST/CIFAR-10 golden inference, multi-frame switching, SPI SRAM readback, and PLL bring-up.
- Built bit-true scoreboard against an SW golden model covering FP16 dequant, multi-channel MAC, max-pool, and 3-stage FC.
- Closed CDC sign-off across 4 async clocks; ran VCS/Verdi regression and coverage via a Python harness with
mem_loadbackdoor.
Status
Silicon back from fabrication and validated by a separate post-silicon team. Pre-silicon verification deliverables — UVM env, vplan, scoreboard, coverage closure — signed off prior to tape-out.
Discussion
Loading comments…
Checking sign-in…